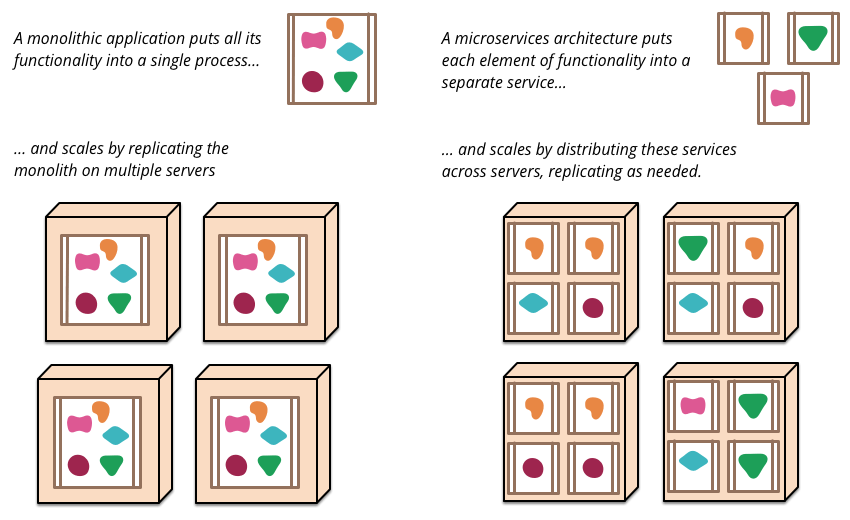
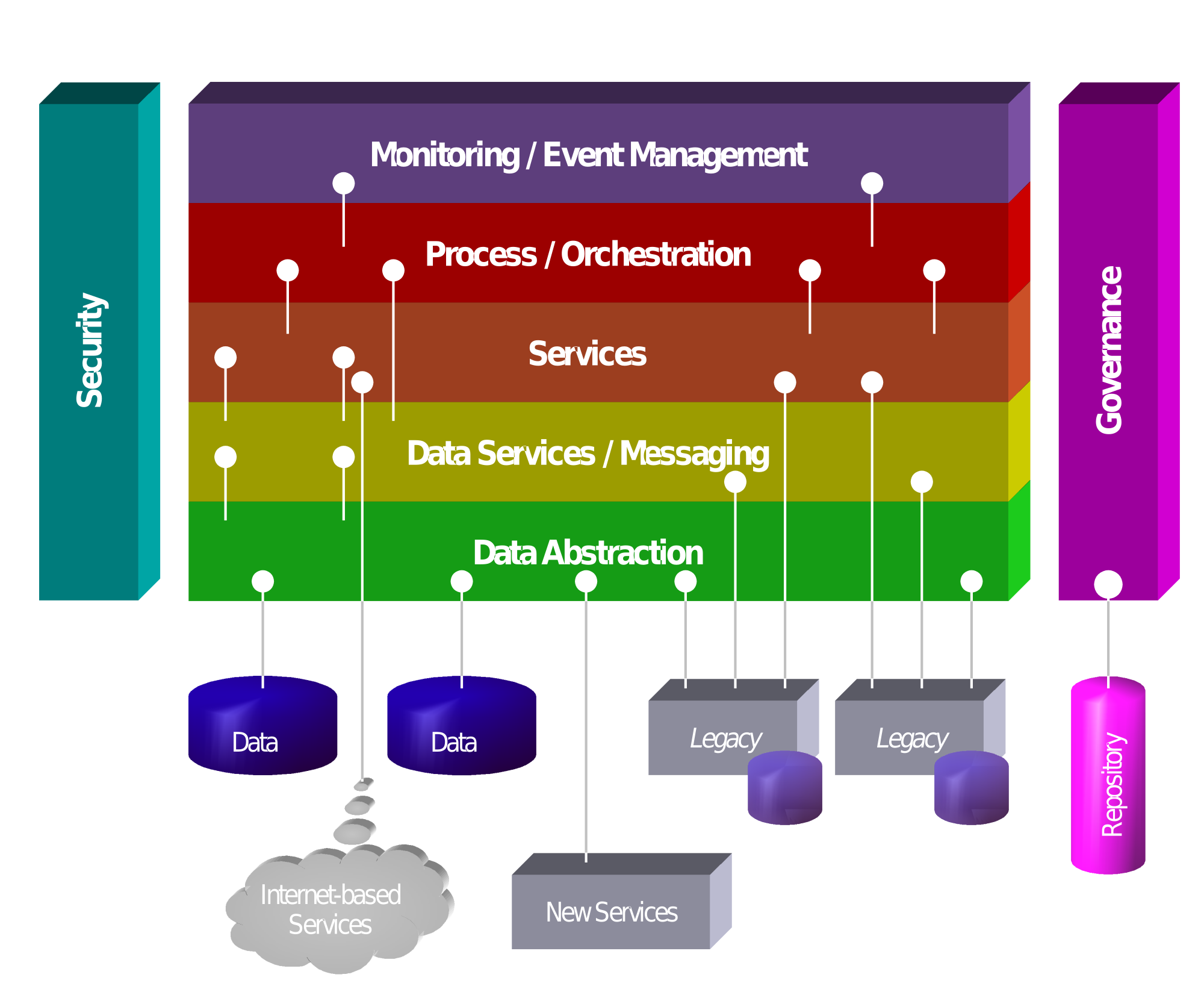
Images thanks to http://martinfowler.com/articles/microservices.html and https://en.wikipedia.org/wiki/Service-oriented_architecture
I’ve been researching and working in the area of modern microservices for the past ~3 to 4 years and have always seen a strong relationship between Modern Microservices with tools and cultures like Docker and DevOps back to Service-Oriented Architecture (SOA) and design. I traced SOA roots back to Gartner Research in 1996 [2] or at least this is what I could find, feel free to correct me here if I haven’t pegged this. More importantly for this post I will briefly explore SOA concepts and design and how they relate to Modern Microservices.
Microservice Architectures (MSA) (credit to meetups and conversations with folks at meetups), are typically RESTful and based on HTTP/JSON. MSA is an architectural style not a “thing” to conform exactly to. In other words, I view it as more of a guideline. MSAs are derived from multiple code bases and each microservice (MS) has or can have its own language it’s written in. Because of this, MSAs typically have better readability and simpler deployments for each MS deployed which in turn leads to better release cycles as long as the organization surrounding the MS teams is put together effectively (more on that later). An MSA doesn’t NEED to be a polyglot of but will often naturally become one because teams may be more familiar with one language over the other which helps delivery time especially if the interfaces between microservices are defined correctly, it truly doesn’t matter most of the time. It also enables scale at a finer level instead of worrying about the whole monolith which is more agile. Scaling a 100 lines of Golang that does one thing well can be achieved much easier when you dont have to worry about other parts of your application that dont need or you dont want to scale in the monolith. In most modern MSAs, the REST interfaces mentioned earlier can be considered the “contract” between microservices in an MSA. These contracts should self describing as they can be, meaning using formats like JSON which is human readable and well-organized.
Overall an MSA doesn’t just have technical benefits but could also mean fewer reviews and approvals because of smaller context boundaries for each microservice team. Better acquisition and on-boarding because you dont have to be so strict about language preference, instead of retooling, you can ingest using polyglot.
Motivations for SOA, from what I have learned, is typically business transformation oriented which shouldn’t be surprising. The enterprise based SOA transformation on a large budget but the motivation is different now with modern MSA, now its quick ROI and better technology to help scale using DevOps practices and platforms.
Some things to consider while designing your modern MSA that I’ve heard and stuck with me:
- Do not create too many services/microservices
- Try not to manage your own infrastructure if you can
- Dont make too many dependencies, (e.g. 1 calls 2 calls 3 calls 4 calls 5 ……)
- Circuit Breaker Pattern, a control point between microservices.
- Bulkhead, do not allow 1 problem affect the entire boat, each microservice has its own data service / database / connection pool, 1 service does not take down the whole system or other microservices.
- Chaos testing (Add it to your test suite!) Example: Chaos Monkey
- You can do microservices with or without service discovery / catalog. Does it over complicate things?
The referenced text[1] that I use for a comparison or similar concepts and differences in this post talk about a vast number of important topics related to Service-Oriented Architecture. Such topics include the overall challenges of SOA, service reuse, deployment efficiency, integration of application and data, agility, flexibility, alignment, reference architectures, common semantics, semantic pitfalls, legacy application integration, governance, security, service discovery, inventory and registration, best practices and more. This post does not go into depth of each individual part but instead this post aims at looking at some of the similarities and differences of SOA and modern microservices.
Service-Oriented Architecture:
Some of concepts of SOA that I’d like to mention (not fully encompassing):
- Technologies widely used were SOAP, XML, WSDL, XSD and lots of Java
- SOAs typically had a Service Bus or ESB (Enterprise Service Bus) a complex middleware aimed at providing access and masking of interfaces.
- Identification and Inventory
- Value chain and business model is more about changing the entire business process
Modern Microservces:
- Technologies widely used are JSON, REST/HTTP and Polyglot services.
- Communication is done over HTTP and the interfaces are abstracted using RESTful contracts.
- Service Discovery
- Value chain and business model is about efficiencies, small teams and DevOps practices while eliminating cilos.
The Bulkhead Analogy
I want to spend a little bit of time on one of the analogies that stuck with me about modern microservices. This was the Bulkhead analogy which I cannot for the life of me remember where I heard it or seem to google a successful author so credit to who or whom ever you are.
The bulkhead analogy is pretty simple actually but has a powerful statement for microservice design. The analogy is such that a MSA, like a large ship is made up of many containers (or in the ships case, bulkheads) that have boundaries between them and hold different component of the ships such as engines, cargo, pumps etc. In MSA, these containers hold different functions or processes that do something wether its handle auth requests, connection to a DB, service a lookup or transformation mechanism it doesn’t matter, just that in both cases you want all containers to be un-damaged for everything to be running the best it can.
The bulkhead analogy goes further to say that if a container gets damaged and takes on water then the entire ship should not sink due to one or few failures. In MSA this can be applied by saying that a few broken microservices should not be designed in a way where there failure would take down your entire application or business process. It essence designs the bulkheads or containers to take damage and remain afloat or “running”.
Again, this analogy is quite simple, but when designing your MSA it’s important to think about these details and is why doing things like proper RESTful design and Chaos testing is worth your time in the long run.
Similarities and Differences or the two architectures / architecture styles:
Given the little glimpse of information I’ve provided above about service oriented architectures and microservices architectures I want to spend a little time talking about the obvious similarities and differences.
Similarities
Both SOA and MSA do the following:
- Code or service reuse
- Loose coupling of services
- Extensibility of the system as a whole
- Well-defined, self-contained services or functions that overall help the business process or system
- Services Registries/Catalogs to discover services
Differences
Some of the differences that stick out to me are:
- Focus on business process, instead of the focus of many services making one important business process MSA focuses on allowing one thing (containerized process) to do one thing and do it well. This allows tighter context boundaries for microservices.
- SOA tailors towards SOAP, XML, WSDL while MSA favors JSON, REST and Polyglot. This is one of the major differences to me, even though its just a tech difference this RESTful polyglot paradigm enables MSAs to thrive with todays developers.
- The value chain and business model is more DevOps centric allowing the focus to be on loosely coupled teams that break down cilos and can focus on faster release cycles and CI/CD of their services rather than with SOA teams typically still had one monolithic view of the ESB and services without the DevOps focus.
Conclusion
Overall this post was mainly a complete high-level overview of what I think are some of the concepts and major differences between traditional SOA and Modern Microservices that stemmed from a course I took during my masters that explored SOA while I was in the industry working on Microservices. The main point I would say I have is that SOA and MSA are very similar but MSA being SOA’s offspring in a way using modern tooling and architecture approaches to todays scaleable data center.
Note* by no means did I cover SOA or MSA to do them any real justice, so I suggest looking into some of the topics talked about here or reading through some of the references below if your interested.
Cheers!
[1] Rosen, Michael “Applied SOA: Service-Oriented Design Architecture and Design Strategies” Wiley, Publishing Inc. 2008
[2] Gartner Research “Service Oriented” Architectures, Part 1:” – //www.gartner.com/doc/code/29201
[3] “SOA fundamentals in a nutshell” Aka Sniv February 2015 http://www.ibm.com/developerworks/webservices/tutorials/ws-soa-ibmcertified/ws-soa-ibmcertified.html












{kind=link}