‘





You might be asking yourself about the information going around about microservices, containers, and the many different tools around building a flexible architecture or “made-of-many-parts” architecture. Well you’re not alone, and there are many tools out there helping (or confusing) you to do so. In this post I’ll talk about some of the different options available like Mesos, Docker Engine, Docker Swarm, Consul, Plugins and more out there. The various different layers involved in a modern microservices architecture have various responsibilities and deciding how you can go about choosing the right pieces to build out those layers can be tough. This post is by far not the only way you can put the layers together and in fact this is MY opinion on the subject given the experience I have had in the ecosystem, it also does not reflect ideas of my employer.
Typically I define modern microservices architecture as having the following layers and responsibilities:
- Applications / Frameworks / App Manifests
- Scheduling
- Orchestration
- Monitoring / Logging / Auditing
- Service Discovery
- Cluster Management / Distributed Systems State
- Data Services and Intelligence
To give you an idea of the tools available and technologies that fall into these categories, here is the list again, but with some of the projects, products and technologies in the ecosystem added. keep in mind this is not an exhaustive list.
*UPDATE: here is separate post aimed at making this a more exhaustive list
- Applications / Frameworks / App Manifests
- Docker Compose YML
- Mesos Frameworks (There are many, see Mesos Application Frameworks)
- Cloud Foundry Application Manifest
- Scheduling
- Fleet
- Marathon (with Mesos)
- Docker Swarm
- Kubernetes Scheduler
- Orchestration (Orchestration is sometimes an overlapping topic)
- Monitoring / Logging / Auditing
- Service Discovery
- Cluster Management / Distributed Systems State
- Flocker Control Service / Agents
- Mesos Slaves
- Kubernetes Nodes/Masters
- Docker Swarm Agents + Master
- Networking
- Docker Libnetwork
- Weaveworks
- Flannel
- Calico
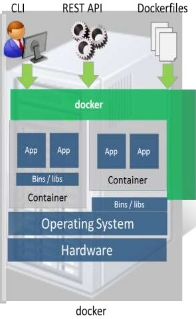
- Container Runtimes
- Docker
- Runc
- Systemd-nspawn
- LXD
- Garden
- Rocket (rkt)
- Data Services and Intelligence
So lets choose a few components, we choose components apart from networking which we leave out here and just use host-only networking with vagrant, but we could add in libnetwork support in Docker directly. For logging and monitoring, we also just spin up DockerUI for this but could also add in loggly, fluentd, sysdig and others.
- Consul – Service Discovery, DNS, K/V Storage
- Docker Engine (Runtime)
- Docker Swarm (Scheduler / Cluster / Distributed State )
- Docker Compose (Orchestration)
- Docker Plugins (Volume integration)
- Flocker (Data Services / Orchestration)
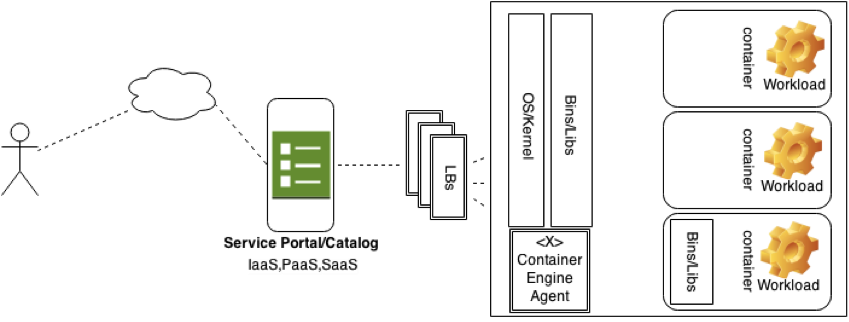
So what do these layers look like all together? We can represent the layers I mentioned above the the following way, including the applications as a logical mapping to the containers running programs and processes above.

Above, we can put together a microservices architecture with the tools defined above, atop of this we can create applications from manifests and schedule containers onto the architecture once this is all running. I want to pinpoint a few specific areas in this architecture because we can add some extra logic to this to make things a little more interesting.
Service Discovery and Registration:
The registration layer can serve many purposes, it is mostly used to register and allow discovery of services (microservices/containers) that are running on a system/cluster. We can use consul to do this type of registration within its key / value mechanisms. You can use Consul’s built-in service mechanism or there are other ways to talk to consul key/value like registrator. In our example we can use the registry layer for something a little more interesting, in this case we can use consul’s locking mechanisms to lock resources we put in them, allowing schedulers to tap into the registry layer instead of talking to every node in the cluster for updates on CPU, Memory etc.
We can add resource updating scripts to our consul services by adding a service to consul’s service mechanism, these services will import keys and values from Facter and other resources then upload them to the K/V store, consul will also health check these services for us as a added benefit.
Below we can see how Consul registers services, in this case we register an “update service” which updates system resources into the registry layer.

We now have the ability to add many system resources, but we also have the flexibility to upload custom resources (facts) like system overload and memory swap free, the below “fact” is a sample of how we can do so giving us a system overload.

Doing so, we can enable the swarm scheduler to use them for scheduling containers. Swarm does not do this today, instead it has only static labels added when the docker engine is started, in this example our swarm scheduler utilizes dynamic labels by getting up-to-date realtime labels that mean something to the system which allows us to schedule containers a little better. What this looks like in swarm is below. See “how to use” section below for how this actually gets used.

Data Services Layer:
Docker also allows us to plug into its ecosystem for volumes with volume plugins which enable containers to add data services like RexRay and Flocker. This part of the ecosystem is rapidly expanding and today we can provision fairly basic volumes with a size, and basic attributes. Docker 1.9 has a volume API which introduces options (opts) for more advanced features and metadata passed to data systems. As you will see in the usage examples below, this helps with more interesting workflows for the developer, tester, etc. As a note, the ecosystem around containers will continue to grow fast, use cases around different types of applications with more data needs will help drive this part of ecosystem.
If your wondering what the block diagram may actually looks like on a per node (server/vm) basis, with what services installed where etc, look no more, see below.

From the above picture, you should get a good idea of what tools sit where, and where they need to be installed. First, every server participating in the cluster needs a Swarm Agent, Flocker-Dataset-Agent, Docker Plugin for Docker, A Consul server (or agent depending how big the cluster, at least 3 servers), and a Docker Engine. The components we talked about above like the custom resource registration has custom facter facts on each node as well so consul and facter can import them appropriately. Now, setting this up by hand is sure to be a pain in the a** if your cluster is large, so in reality we should think about the DevOps pipeline and the roll of puppet, or chef to automate the deployment of a lot of this. For my example I packed everything into a Vagrantfile and vagrant shell scripts to do the install and configuration, so a simple “vagrant up” would do, given I have about 20-30 minutes to watch the cluster come up 🙂
How do I use it!!?
Okay, lets get to actually using this microservices cluster now that we have it all set. This section of the blog post should give you an idea of the use cases and types of applications you can deploy to your microservices architecture and what tooling to use given then above examples and layers we introduced.
Using the Docker CLI with Swarm to schedule new resources via constraints and volume profiles.
This will look for specific load between 0-25% because we have a custom registration layer. *(note, some of the profiles work was in collaboration Mahuri from CHQ and Sean Dell for the Docker Global Hackday #3)
docker run -d -e constraint:system_overload_10min==/[0-2][0-5]/ -e constraint:architecture==x86_64 -e constraint:virtual=virtualbox -e constraint:selinux_enforced=false -v myVol@gold:/data/ redis
Using Docker Compose with Flocker volume driver that supports storage profiles:
This will schedule a redis database container using the flocker volume driver with a “gold” volume, meaning we will get a better IOPS, Bandwidth and other “features” that are considered of more performance and value.

Using Docker compose with swarm to guarantee a server has a specific volume driver and to schedule a container to a server with a specific CPU Overload:
In this example we also use the overload percentage resource in the scheduler but we also take advantage of the registry layer knowing which nodes are running certain volume plugins and we can schedule to Swarm knowing we will get nodes with a specific driver and hypervisor making sure that it will support the profile we want.

A use case where a developer wants to schedule to specific resources, start a web service, snapshot an entire database container and its data and view that data all using the Docker CLI.
This example shows how providing the right infrastructure tooling to the Docker CLI and tools allows for a more seamless developer / test workflow. This example allows us to get everything we need via the docker CLI while never leaving our one terminal to run commands on a storage system or separate node.
Start MySQL Container with constraints: docker run -ti -e constraint:is_virtual==True -e constraint:system_overload_10min==/[0-2][0-5]/ -v demoVol@gold:/var/lib/mysql --volume-driver=flocker -p 3306:3306 --name MySQL wallnerryan/mysql
Start a simple TODO List application: docker run -it -e constraint:is_virtual==True --rm -e DATABASE_IP=192.168.50.13 -e DATABASE=mysql -p 8005:8080 wallnerryan/todolist
We want to snapshot our original MySQL database, so lets pull the dataset-ID from its mount point and input that into the snapshot profile.
docker inspect --format='{{.Mounts}}' MySQL
[{demoVol@gold /flocker/f23ca986-cb43-43c1-865c-b57b1023ab7e /var/lib/mysql flocker z true}]
Here we place a substring of the the Dataset ID into the snapshot profile in our MySQL-snap container creation, this will create a second MySQL container with a snapshot of production data. docker run -ti -e affinity:container==MySQL -v demoVol-snap@snapshot-f23ca986:/var/lib/mysql --volume-driver=flocker -p 3307:3306 --name MySQL-snap wallnerryan/mysql
At this point we have pretty much been able to snapshot the entire MySQL application (container and data) and all of its data at a point in time while scheduling the point in time data and container to a specific node in one terminal and few CLI commands where our other MySQL database was running. In the future we could see the option to have dev/test clusters and have the ability to schedule different operations and workflows across shared production data in a microservices architecture that would help streamline teams in an organization.
Cheers, Thanks for reading!





































{kind=link}
{kind=link}
{kind=link}